A ConvNet for the 2020s (ConvNeXt)
Main Idea
Vision Task에 Transformer 기반 Architecture를 접목하는 ViT의 등장 이후, classification task에 대해 좋은 성능을 보였습니다. ViT 이후에 Swin Transformers 등의 방법론 등은 segmentation이나 object detection에도 transformer를 적용하기 위해 등장한 방법들이었습니다. Swin Transformer의 경우, 여러 ConvNet을 prior로 삼는 hybrid한 방법으로 이를 해결한 것이 특징입니다. 하지만, hybrid하다고 하기에는 기존 Transformer의 힘을 빌린 것일 뿐, ConvNet 자체가 가지고 있는 inductive bias를 최대한 사용한 방법은 아닙니다.
저자는 순수한 ConvNet(Transformer 구조를 곁들이지 않은)의 힘을 확인하고자 기존의 standard ResNet(architecture + 학습 방법론)에서 vision Transformer처럼 학습할 수 있게끔 지금까지 등장해온 여러 Novelty들을 접목해보고자 시도합니다. 특히, vision Transformer 모델들이 등장할 때 항상 새로운 학습 방법론을 함께 들고 나와서 성능 향상을 주장하고는 하는데, 그 학습 방법론들을 기존 ConvNet들에 적용해본 사례가 많이 없습니다. 여러 실험을 통해 최근에 등장한 학습 방법론을 적용하고 convolution block design을 새롭게 디자인하면 더 직관적인 구조로 Transformer에 근접한 성능을 보일 수 있음을 보여줍니다.
가끔 ConvNeXt 논문을 들어보기만 하고 착각하는 것 중 하나가, ConvNeXt의 FLOPs가 Transformer보다 현저히 작은 채로 성능을 비등하게 낸 것으로 아시는 분들이 있습니다. ConvNeXt는 architecture가 (inductive bias에서 등장했던) ConvNet을 순수하게 기반으로 했을 뿐, 그 모델 사이즈가 Transformers보다 절대 작지는 않습니다. 다만, 상대적으로 Transformer보다는 convolution layer에 대한 compression 방법론들이 더 많이 고안된만큼, 그 직관적인 구조에 의해 등장했던 compression 방법론들을 두루 적용하여 앞으로 경량화할 수 있는 가능성이 좀 더 있다는 게 제 개인적인 생각입니다.
주로 ResNet 50을 기준으로 성능 report를 진행하고, 각 accuracy는 random seed를 다르게 하여 3번씩 실험한 결과입니다.
Background Knowledge
Examples of Representative ConvNet
VGGNet, Inceptions, ResNe(X)t, DenseNet, MobileNet, EfficientNet and RegNet
ConvNet의 주요 특징들
아래는 "sliding window"를 사용하는 convolution에서 고안되었기 때문에 생겨나는 특징들입니다.
- Translation equivariant — Object detection 등의 Task에 있어서 특히 유용합니다. 가끔 equivariance, invariance 헷갈려 하시는 분들 계셔서 말씀드리면, Patch를 이동하든, 그 결과값을 이동한다고 feature vector 값이 바뀌는 건 아니여서 invariant 하다고도 볼 수 있습니다. (g: Identity Mapping)
- Weight Sharing
변화1: Training Methodology
저자는 ResNet 50에 DeiT, Swin Transformer와 유사한 training recipe를 적용하여 성능 향상이 얼마나 일어나는 지를 살펴봅니다.
- Training epoch 증가: 90 → 300
- Optimizer 변경: Adam → AdamW
- Data augmentation: Mixup, Cutmix, RandAugment, Random Erasing을 추가
- Regularization scheme 추가:
- Stochastic depth — Depth를 이루는 ResBlocks 중 일부를 random하게 drop하면서 학습하는 방법입니다.
- Label smoothing
이 방법론 변경을 통해 아래와 같은 성능 향상이 있었습니다.
- ResNet-50: 76.1% → 78.8% (+2.7%)
어쩌면 traditional ConvNets와 vision Transformers의 차이는 학습 방법에서 주로 기인한 게 아닐까 싶을 정도의 차이일 수도 있습니다.
변화2: 큰 틀에서의 구조 변경
Stage Compute Ratio를 (3, 3, 9, 3)으로 변경
기존 ResNet의 stage별 디자인은 매우 경험적으로 결정되었습니다.
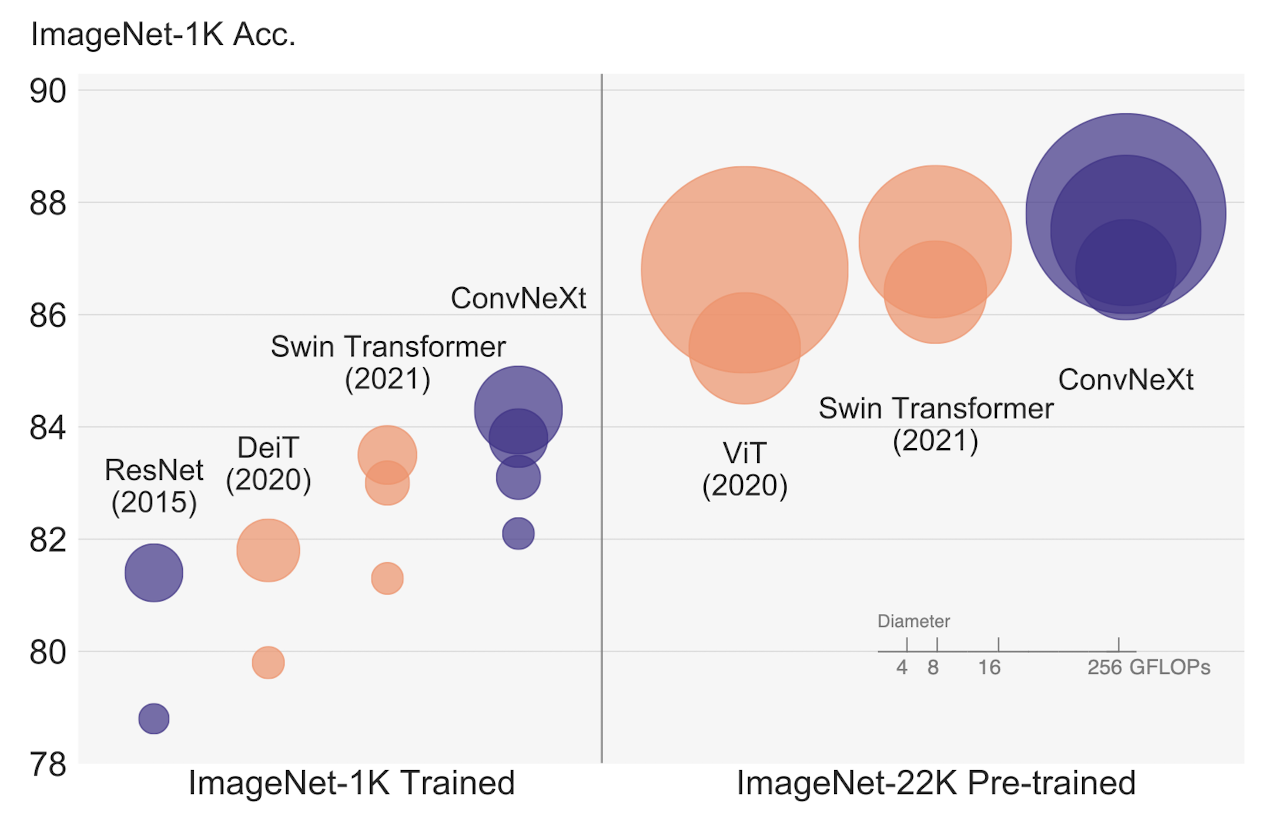
Swin Transformer는 이와는 비슷하나 조금 다른 stage ratio를 보여주는데, 작은 모델의 경우 (1, 1, 3, 1), 큰 모델의 경우 (1, 1, 9, 1)의 비율을 보여줍니다. 저자는 Swin-T와의 FLOPs를 유사한 비율로 가져가기 위해, 기존의 stage ratio (3, 4, 6, 3)을 (3, 3, 9, 3)으로 변경했습니다.
- ResNet-50: 78.8% → 79.4% (+0.6%, 누적: +3.3%)
Patch를 만드는 첫 stem layer을 Conv(ks=4, stride=4)로 변경
Stem cell design은 아키텍쳐 가장 처음에 input image를 어떻게 처리해줄 지를 담고 있습니다. ResNet에서는 kernel size 7x7, stride 2의 Conv layer(2x downsample)과 max-pooling(2x downsample)을 통해 4x downsample 시키는 stem cell design을 사용했습니다. Vision Transformer들은 이보다도 더 과감하게 patch를 만드는 전략을 사용하는데, 14x14 또는 16x16의 아주 큰 kernel size를 가진 Conv layer를 겹치는 부분이 없게끔(kernel size와 stride가 동일) 설정합니다.
저자는 ResNet-style stem cell로서 kernel size 4x4, stride 4로 설정한 conv. layer(4x downsample)를 stem cell design으로 선정했습니다.
- ResNet-50: 79.4% → 79.5% (+0.1%, 누적: +3.4%)
변화3: ResNeXt 아이디어 적용하기
ResNeXt에서는 bottleneck block에서 grouped convolution을 사용함으로서, FLOPs를 줄이고 network width(# channel in hidden layers)를 늘릴 수 있었습니다. 저자는 grouped convolution의 맥락에서 depthwise convolution을 사용합니다. Depthwise convolution은 per-channel로 self-attention의 weighted sum과 동일한 역할을 하게 되는데요. 즉, spatial dimension으로만 정보를 섞는 역할을 합니다.
Width를 Swin Transformer를 따라 64에서 96으로 늘리게 되었습니다.
- ResNet-50: 79.5% → 80.5% (+1.0%, 누적: +4.4%)
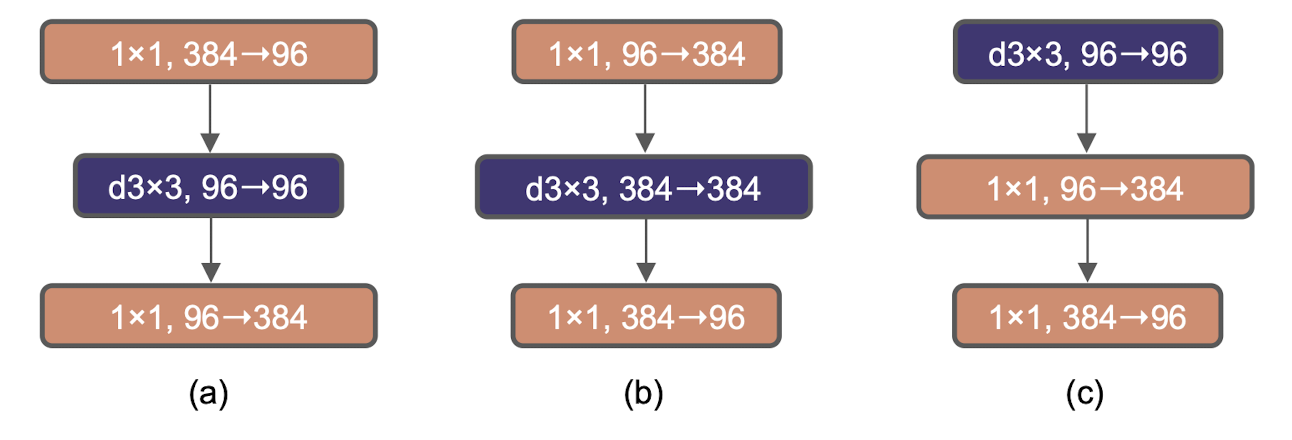
(a): ResNeXt block / (b): inverted bottleneck / (c): position switch of depthwise conv layer
변화4: Inverted Bottleneck 적용하기
Transformer에서의 inverted bottleneck은 MLP block 중 hidden layer의 dimension이 input dimension보다 4배 크게 디자인 된 것을 말합니다. ConvNet에서도 inverted bottleneck은 MobileNetV2에서 등장한 이후 두루 쓰이고 있습니다. Depthwise convolution의 FLOPs는 늘어나지만 전체 네트워크의 FLOPs는 줄어드는데, 이는 downsampling을 진행하는 residual block 내의 1x1 conv layer(shortcut layer)의 FLOPs가 줄어들기 때문입니다.
- ResNet-50: 80.5% → 80.6% (+0.1%, 누적: +4.5%)
변화5: 큰 사이즈의 Kernel을 이용하기
Vision Transformer에서 사용하는 self-attention은 non-local한 특성을 가지고 있어, 사실상 receptive field가 global하다고 볼 수 있습니다. ConvNet에서는 GPU의 특성을 고려하여 효율적인 연산을 위해 VGG network를 시작으로 3x3의 작은 사이즈의 kernel 사이즈를 사용했습니다. Swin Transformer는 self-attention을 사용하는 데에 있어 local window를 적용하는데, 여기서는 kernel size를 최소 7x7로 잡아서 사용했었습니다.
우선 kernel size를 키우기 위해서는 depthwise conv.의 위치를 1x1 conv. 앞으로 가져와야 합니다. 이는 Transformer에서 MSA(Multi-head Self Attention)가 MLP layer 앞에 있는 구조와 유사하게 가져가기 위함입니다.
저자들의 실험을 통해 7x7보다 큰 kernel에서는 성능이 더 증가하지 않고 saturate 되는 것을 확인했습니다. FLOPs는 4.6G에서 4.2G로 낮출 수 있었습니다.
변화6: Activation, Normalization Layer 변경하기
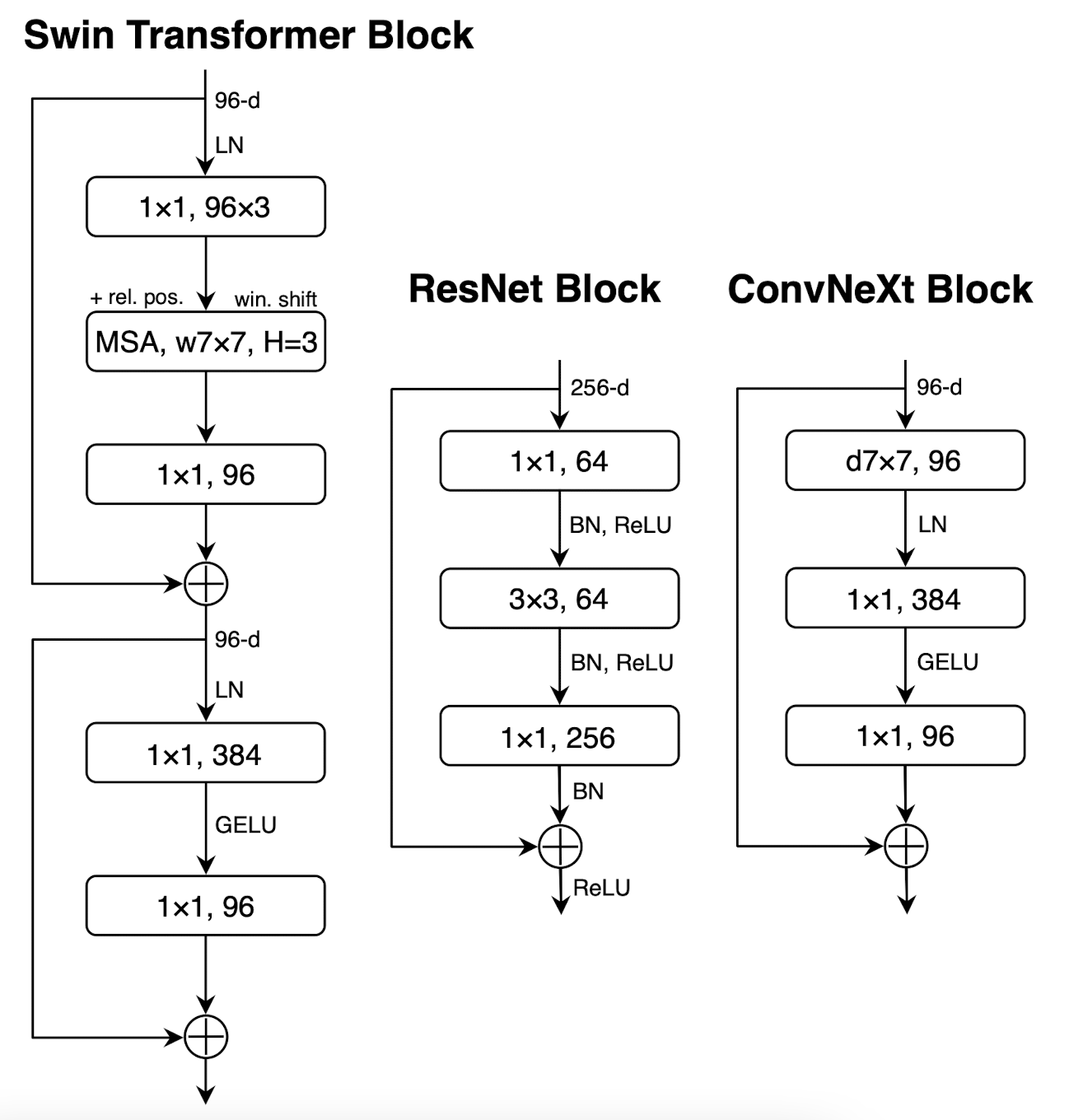
가장 우측 ConvNeXt block이 저자가 최종적으로 디자인한 형태입니다.
ReLU를 GELU로 변경
ConvNet에서는 아직도 ReLU가 두루 쓰이고, original Transformer 논문에서도 ReLU를 사용하지만, 그 이후 등장한 NLP Transformer(BERT, GPT-2)와 ViT에서는 GELU(Gaussian Error Linear Unit)를 많이 사용합니다. 이를 적용했을 때, 별도의 성능 향상은 없었지만, GELU가 ConvNet에도 적용될 수 있음을 보여줍니다.
Activation Function을 적게 쓰기
Transformer block에서도 MLP block 내 activation 1번 쓰이는 것 외로는 쓰이지 않습니다. 저자는 Transformer block design을 따라, residual block 내에 모든 GELU activation을 지우고, 1x1 layer 사이에 activation 하나만 남겨두었습니다.
- ResNet-50: 80.6% → 81.3% (+0.7%, 누적: +5.2%) — 이 성능은 Swin-T와 동일합니다.
Normalization도 적게 쓰기
저자는 1x1 conv 앞에 하나의 BN(Batch Normalization)만을 놔두고, 나머지 normalization layer를 지웠습니다.
- ResNet-50: 81.3% → 81.4% (+0.1%, 누적: +5.3%)
Batch Normalization 대신 Layer Normalization
Transformer에서는 이미 LN을 쓰면서 좋은 성능을 보인 경우가 많았습니다. 저자는 이 상태에서 LN을 적용해서도 학습하는 데 무리가 없음을 확인했고 오히려 성능이 향상되었습니다.
- ResNet-50: 81.4% → 81.5% (+0.1%, 누적: +5.4%)
Separate Downsampling Layer 사용
Swin Transformer가 patch merging을 할 때 2x2 neighborhood patch들의 channel을 concat하여(4C) 이에 대해 2C의 channel size가 되도록 내뱉습니다. 저자는 ResNet에서 kernel size 3x3, stride 2, padding 1로 마치 공식처럼 쓰이던 downsample conv. layer 대신 Swin Transformer에서의 downsample 방식을 사용합니다. 학습이 diverge 되는 것을 방지하기 위해 block-level에서 spatial resolution이 변경되는 지점에 LN을 넣어주면 학습이 stabilize 됩니다.
- ResNet-50: 81.5% → 82.0% (+0.5%, 누적: +5.9%)
Training Details
(Pre-)Training Settings
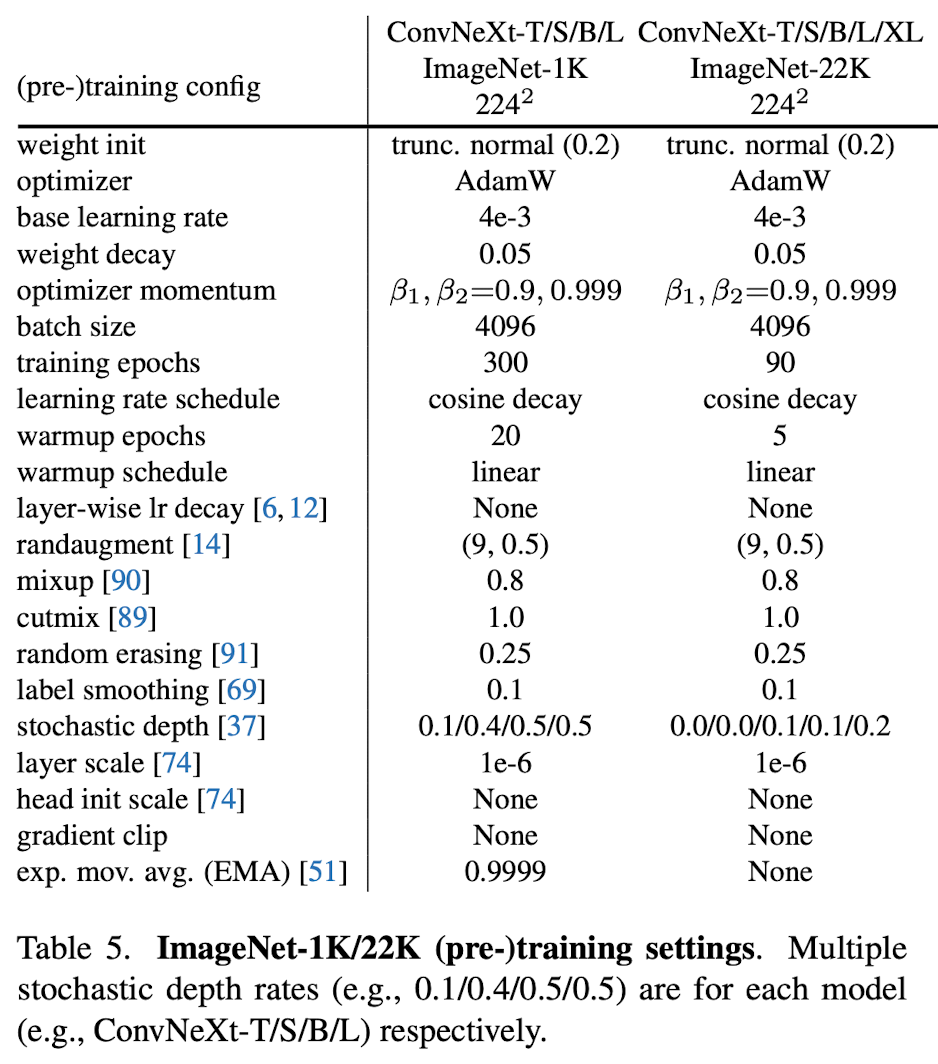
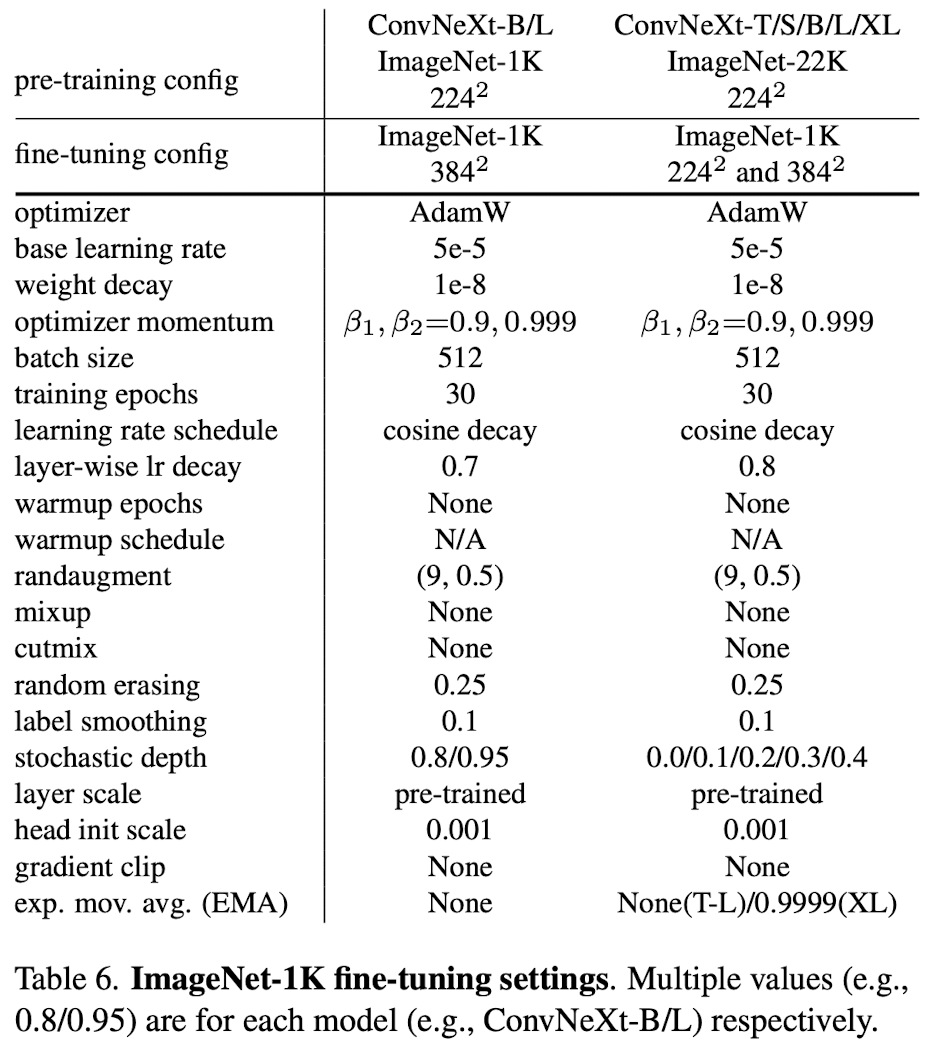
Finetuning Settings