Activate or Not: Learning Customized Activation (ACON)
Ma, Ningning, et al. "Activate or Not: Learning Customized Activation."
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
먼저 알면 좋은 것들
Swish Activation Function
swish(x) := x × σ(βx) = x / (1 + e-βx)
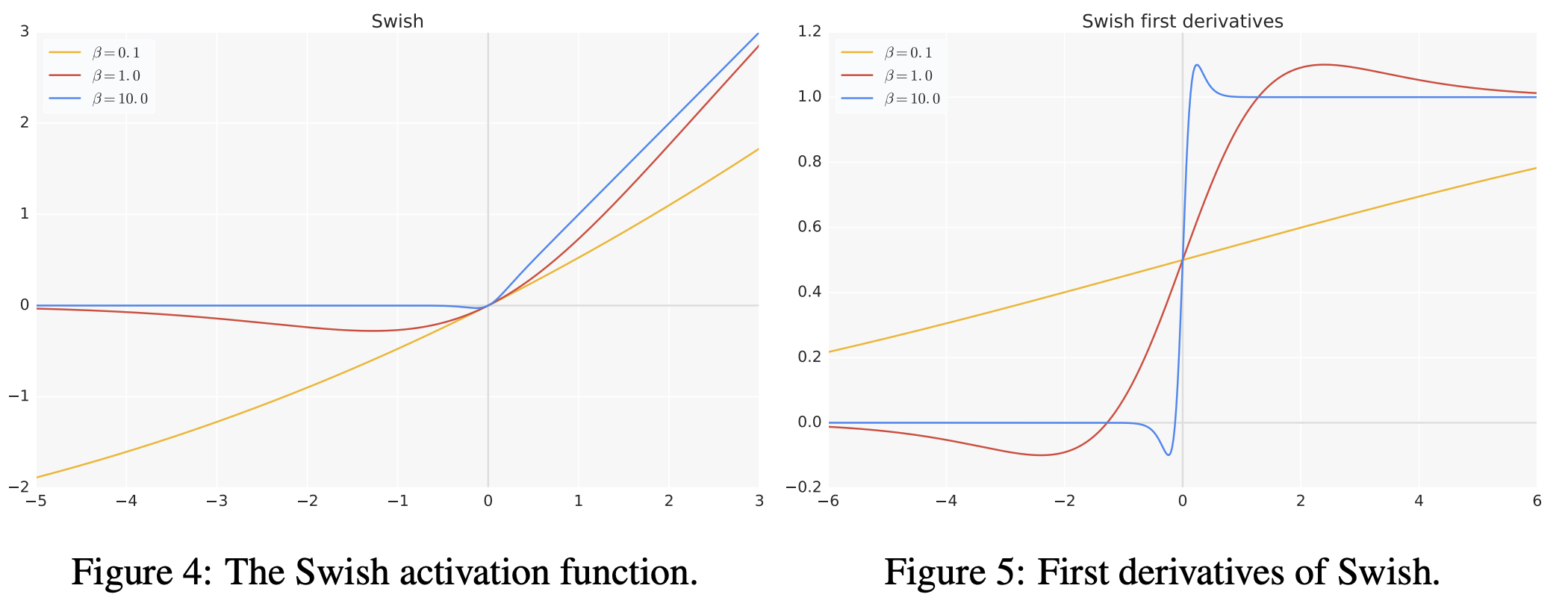
- Linear Function과 ReLU 사이에서의 non-linearly interpolated activation을 보여줍니다.
- β = 0일 경우, Linear function f(x) = x/2 처럼 작용하게 됩니다.
- 반대로 β → ∞일 경우, Sigmoid에 해당하는 부분이 0-1 activation처럼 작용하게 되어, Swish가 ReLU처럼 작용하게 됩니다.
- β = 1일 경우, 강화학습에서 사용되는 Sigmoid-weighted Linear Unit (SiL) function처럼 작용할 수 있습니다.
- β는 어떤 상수일 수도 있고, 모델에 따라서는 훈련 가능한 파라미터가 될 수도 있습니다.
- Generative Model에서도 ReLU 대신 사용하는 경우가 많이 있습니다.
- 최근에는 Implicit Representation Network 상에서도 Swish가 다시금 주목을 받고 있습니다.
Sigmoid
σ(x) = 1 / (1 + e-x)
여기서는 Activation으로 시사하기보다는 수식 표현 시에 sigmoid로 묶어 표현하기 위해 확인하고 넘어가야 합니다. Swish가 결국 input 값에 sigmoid한 것과 input 값의 곱으로 표현된다(β를 곱하기는 하겠지만)는 것도 다시 한번 리마인드하고 넘어갑시다.
Maxout Family
ReLU와 같은 Activation Function의 출발점에 해당하는 개념 중 하나입니다. Goodfellow와 Bengio의 논문으로, Maximum을 선택하는 것으로도 임의의 Convex Function에 대해 두루 근사할 수 있음을 시사합니다.
Main Idea
ACON (ActivationOrNot) Activation Function
ACON-C(x) := (p1 - p2)x · σ(β(p1 - p2)x) + p2x
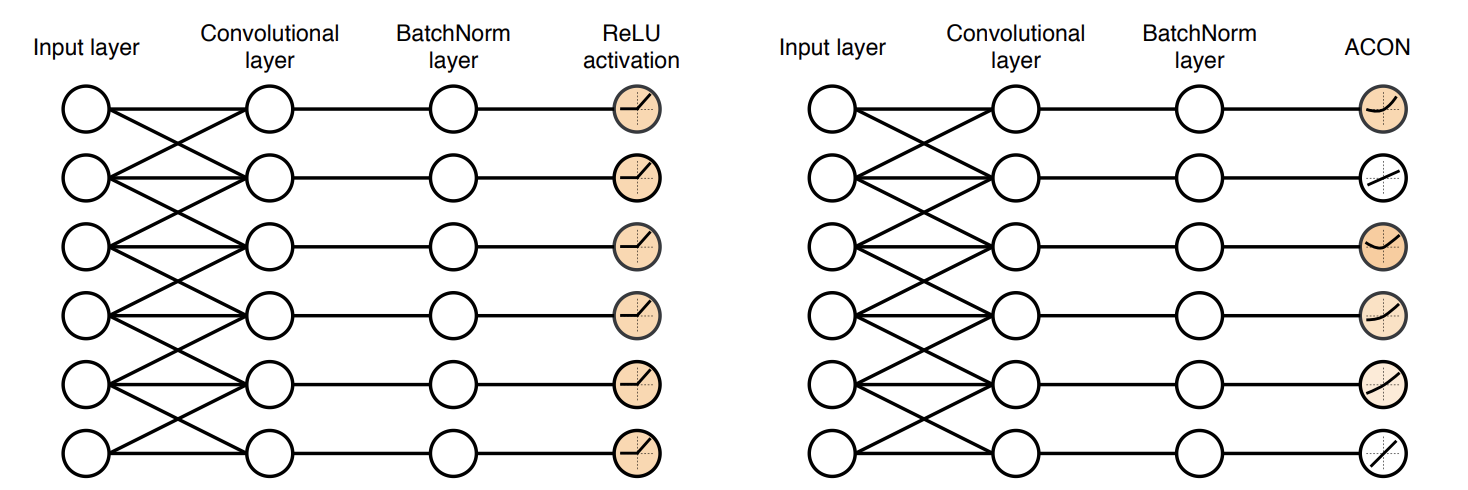
ACON Activation을 사용하였을 때, 특정 Layer의 Activation이 Linear하게 pass할 수도, Non-linear Activation으로 활성될 수도 있습니다.
저자는 ACON(더 나아가서 Meta-ACON)이라고 하는 Activation Function을 제안합니다. ACON activation은 trainable한 activation으로 Neuron을 Activation할 지 안 할지를 각 Layer의 특성에 맞게 결정합니다.
어떻게 해서 ACON 식을 도출할 수 있게 되었을까요?
먼저 Maximum Function max(x1, ..., xn)에 대해 smooth된 버전을 보아야 합니다. Maximum을 구한다는 것은 일반적으로 differentiable하지 않지만, 이를 smooth한 함수는 differentiable하게 됩니다.
이 때, β는 switching factor로서:
- β → ∞일 때, 주어진 함수는 Maximum Function의 역할을 하게 됩니다.
- β → 0일 때, 주어진 함수는 산술평균(Arithmetic Mean)처럼 작동합니다.
일반적으로 Neural Network에서 많이 사용하는 Activation Function들은 Maxout에 준하는 것으로 표현할 수 있습니다: max(ηa(x), ηb(x))
예를 들어, ReLU는 ηa(x) = x, ηb(x) = 0인 것으로 생각하면, 이 역시 Maxout Family에 속한다고 볼 수 있습니다. Leaky ReLU, FReLU 등도 모두 Maxout Family에 속하게 됩니다.
본 논문에서의 목표는 Maximum Function과 Maxout Family를 함께 사용하여, Maxout Family 각각에 상응하는 activation function들을 smooth한 함수로 근사해보는 것입니다.
ACON 안에 Swish 있다

ReLU의 smooth되는 버전이 Swish라는 건 직관으로도 많이들 이해하고 있었는데요. Smooth된 Maximum Function에 대입해서 전개해보면, 바로 Swish 식이 나오게 됩니다. 저자는 이를 통해 Swish가 ReLU의 Smooth Approximation임을 표현할 수 있게 된다고 말합니다.
또한, PReLU(Parametric ReLU)도 살펴보면, 역시 Smooth되는 함수로 대응하는 것을 찾을 수 있습니다. 그리고 마지막으로 각 선형 함수의 가중치가 p1, p2로 표현하면 가장 일반화된 표현이 되고, 여기에 각각 Maxout Family, ACON Family를 대응해보면 일반화된 ACON-C 식이 유도됩니다.
ACON의 특성
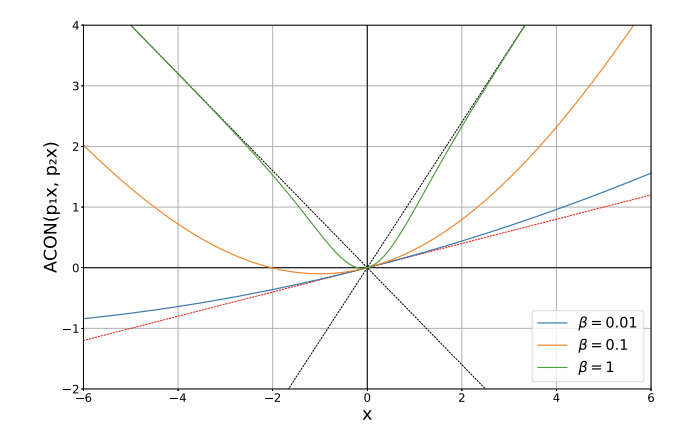
p1=1.2, p2=-0.8일 때 ACON-C에 대응하는 식을 여러 β값에 대해 표현한 graph입니다.
- β가 클 때는, maximum function처럼 반응하여 비선형적인 특성을 갖게 됩니다.
- β가 0에 가까울 때는 mean function에 근사되어 선형적인 특성을 갖습니다.
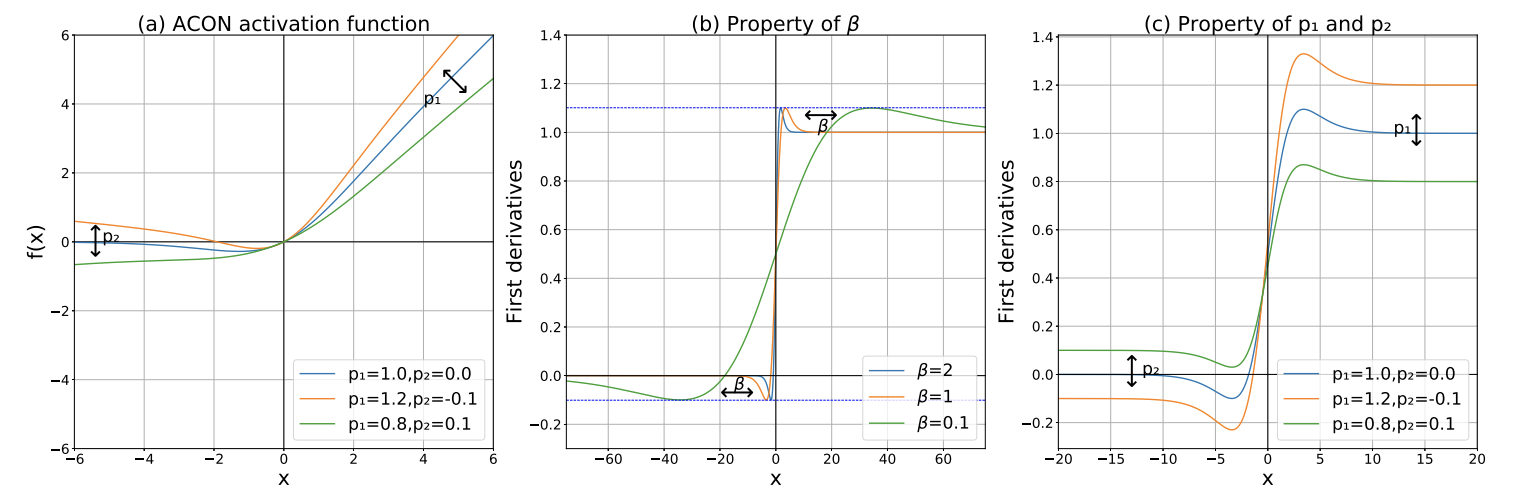
ACON Activation과 이에 대한 도함수(derivative)를 보여주는 그림입니다.
- 왼쪽: β가 fixed 되어 있을 때, p1, p2 계수에 따라 Activation function이 달라지는 것을 보여줍니다.
- 가운데: β 값이 달라짐에 따라 ACON의 도함수가 변화합니다.
- 오른쪽: β가 fixed 되어 있을 때, p1, p2 계수에 따라 ACON의 도함수가 어떻게 변하는 지를 보여줍니다.
ACON의 도함수를 보면서 아래와 같은 사실을 알 수 있습니다:
- p1, p2는 각각 Upper/Lower Bound에 해당하는 값을 결정하게 됩니다.
- β 값은 도함수 상에서 p1, p2에 의해 결정된 Upper/Lower Bound에 얼마나 빠르게 근사되는 지를 결정합니다.
Swish에서는 Hyperparameter β만이 Upper/Lower Bound에 얼마나 빨리 근사되는 지를 결정하게 되는데요. ACON에서는 p1, p2가 이 Bound 값을 결정하게 되고, 이 역시 learnable해질 수 있다는 특성이 있습니다. 이렇게 boundary가 learnable하다는 것은 optimization을 쉽게 하는 데에 필수적인 특성입니다.
학습에 모두 맡겨버리자! Meta-ACON
Meta-ACON은 β 자체를 Learnable한 parameter로 놔두는 것에서 더 나아가, Layer에 입력되는 feature map으로부터 FC Layers를 거쳐 estimation 되도록 만든 것입니다.
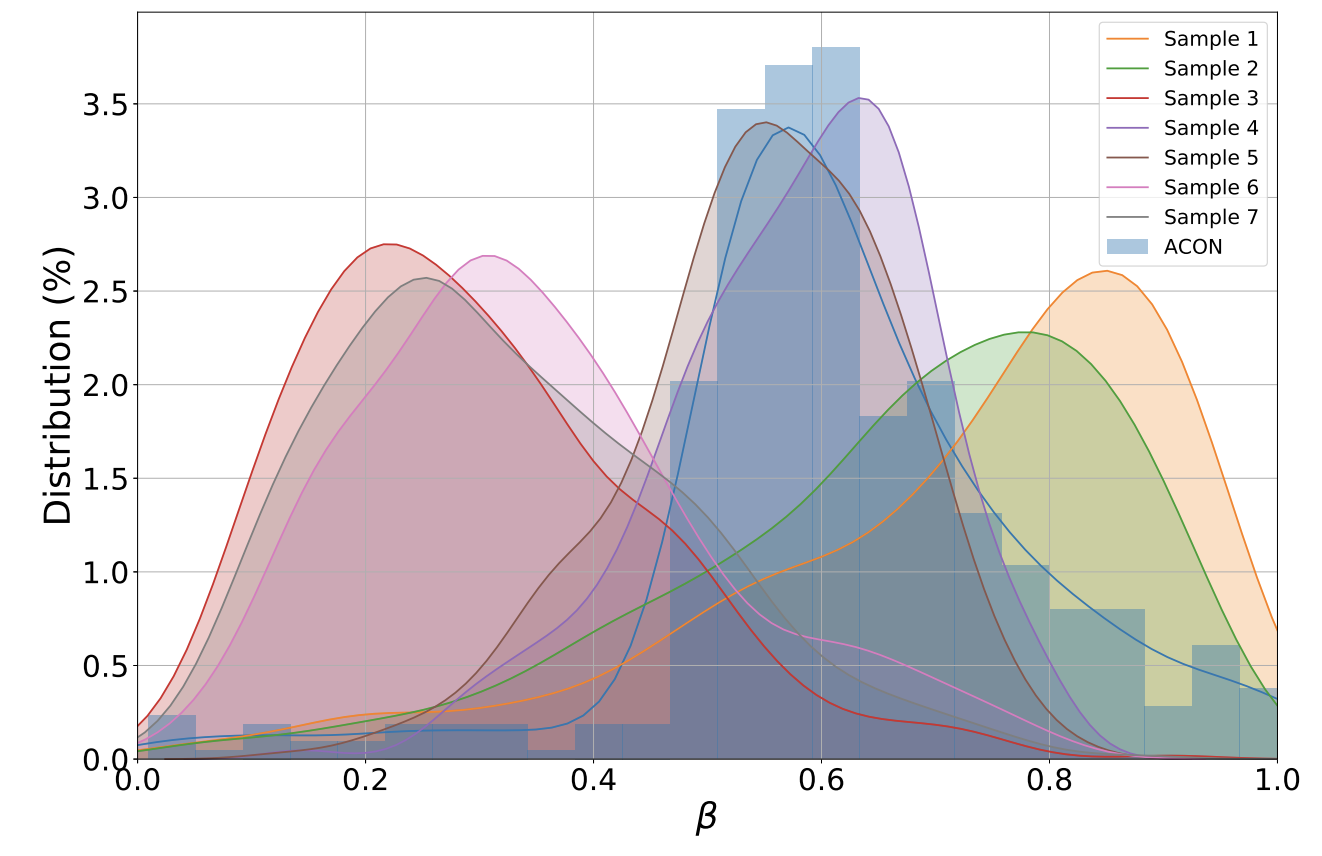
ACON과 Meta-ACON을 비교한 도식입니다. ResNet50의 마지막 BottleNeck Layer에서의 activation을 비교한 것입니다.
- ACON에서 추출할 경우, 7개의 sample이 동일한 β distribution을 나타냅니다.
- Meta-ACON에서는 7개의 sample이 서로 다른 β distribution을 보여줍니다. β 값이 작을수록 선형적으로, β 값이 클수록 비선형적으로 반응합니다.
결과
ImageNet Classification에 대한 ShuffleNetV2 기준 결과를 살펴보면, 학습 속도도 빠를 뿐더러, Meta-ACON을 사용했을 때 Error rate가 낮아지는 것을 확인할 수 있습니다. 또한, 전반적으로 모델 사이즈가 커질수록, Meta-ACON을 사용할수록 Accuracy 향상이 큽니다.
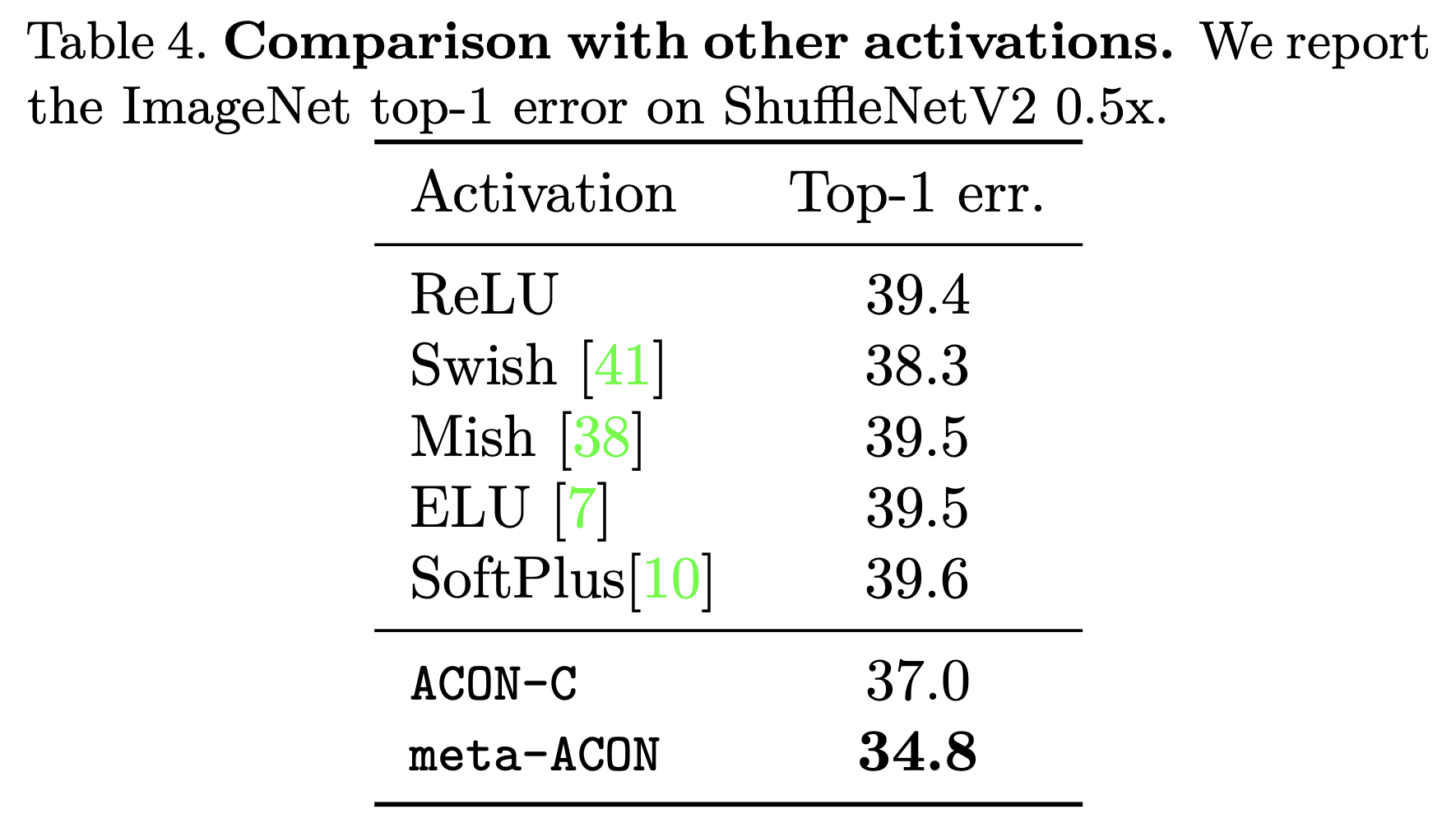
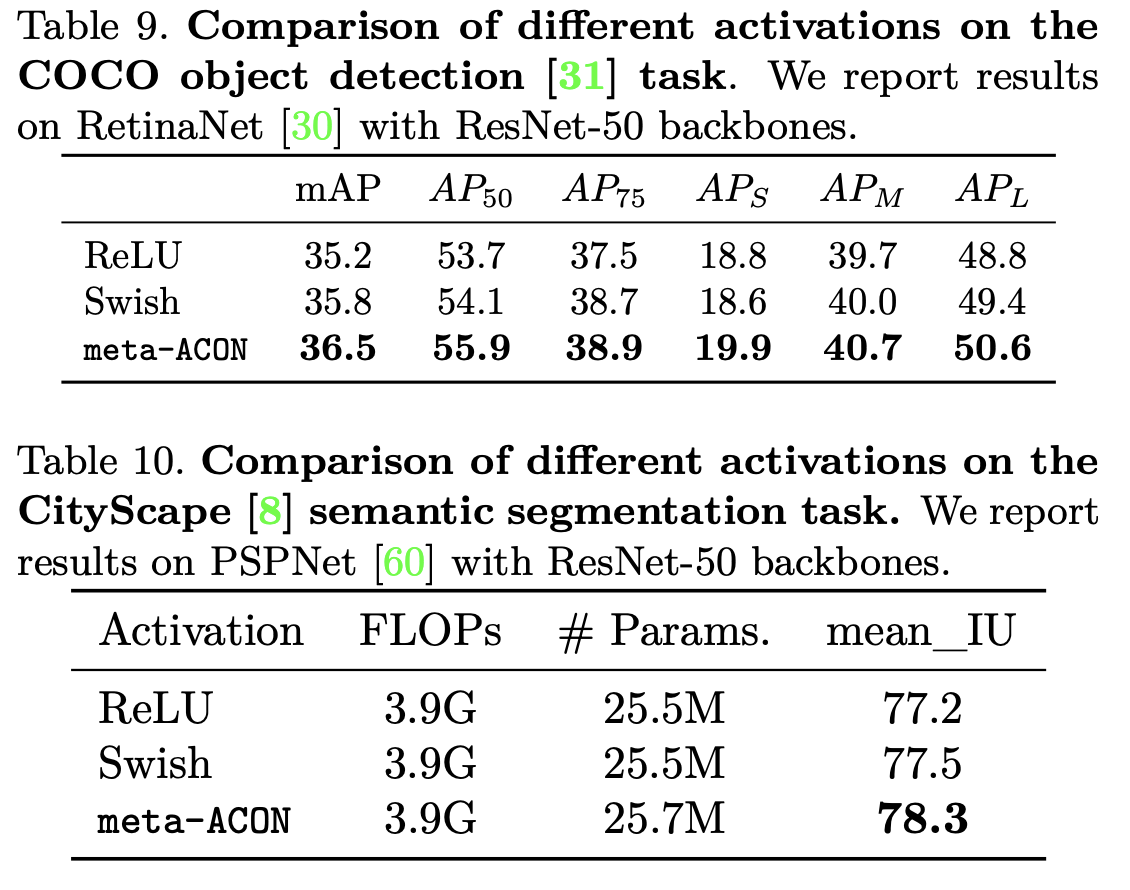
Meta-ACON은 다른 activation 대비 ImageNet Classification에서 좋은 성능을 보여주고 있습니다. 또한, 특정 backbone에 대해서 Object Detection 및 Semantic Segmentation에 있어서도 다른 activation function을 사용할 때보다 좋은 성능을 보여줍니다.
마무리
ReLU와 Swish 간의 관계를 통해 새로운 Activation Function들이 포진되어 있을만한 일반화된 식을 찾고(ACON Family), 이를 기반으로 Trainable한 Activation Function을 새로 만나볼 수 있었습니다.
사실 이렇게 훈련 가능한 파라미터를 가진 Activation Function이 ACON만 처음인 것은 아닙니다. 또한, 여러 Sub-task에 대해 범용적으로 사용될 수 있는 Activation Function일지는 미지수이기도 합니다. 다만, 식에 대한 간단한 정리로 ReLU와 Swish 간의 관계를 보임과 동시에, 새로운 Activation Family를 제시했다는 데에 의의가 있는 논문이었습니다.
TL;DR
- Activation function들에 대해 기존 Maxout family에 해당하는 일반화를 넘어 ACON Family라는 개념으로 확장하여 일반화를 합니다.
- 이를 통해 ACON Family에서 각 activation을 결정 짓는 parameter 자체를 learnable하게 하여 ACON이라는 activation을 새롭게 제시합니다.
- 기존 Swish는 NAS로 찾은 activation으로서, 더 좋다는 것만 알 뿐, 왜 좋은지를 몰랐는데, ACON Family에 대응하여 봤을 때, 이를 어느정도 설명할 수 있게 됩니다.
References
- Ramachandran, Prajit, Barret Zoph, and Quoc V. Le. "Searching for activation functions." arXiv preprint arXiv:1710.05941 (2017). [paper]
- Goodfellow, Ian, et al. "Maxout networks." International conference on machine learning. PMLR, 2013. [paper]
- Han Cai, Chuang Gan, Ligeng Zhu, and Song Han. "TinyTL: Reduce Memory, Not Parameters for Efficient On-Device Learning." NeurIPS 2020. [paper]