
Publications
Introduces Mirage, a diffusion-based model that generates realistic talking-head video directly from audio input, enabling scalable A-roll video creation.

Distills compact Stable Diffusion variants that achieve 30–50% faster and smaller, more cost-efficient inference without sacrificing image quality, including deployment on NVIDIA Jetson devices.

Proposes a task-agnostic pruning method for latent diffusion models, achieving efficient compression without retraining on specific downstream tasks.
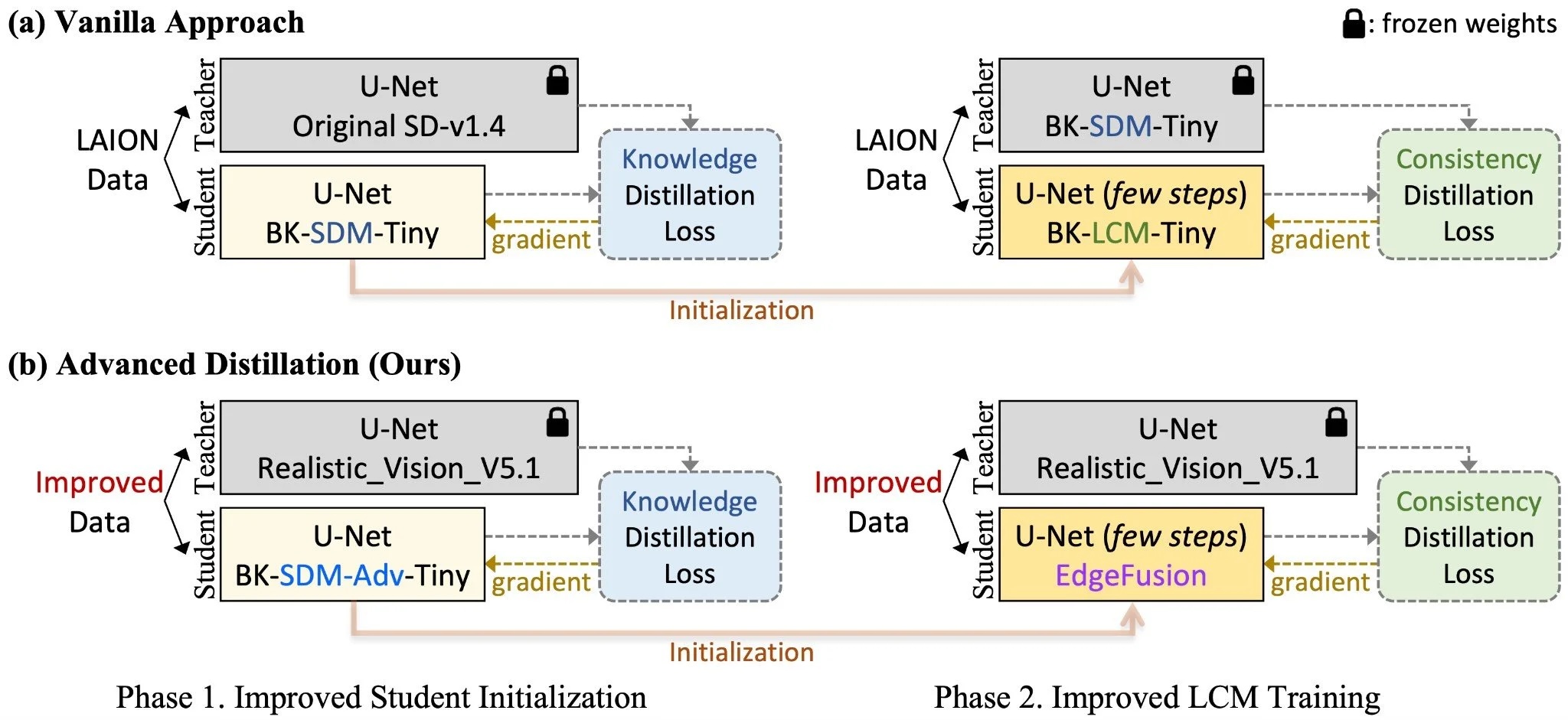
Demonstrates subsecond text-to-image generation on smartphone by combining model compression techniques including knowledge distllation, step distillation, and quantization.
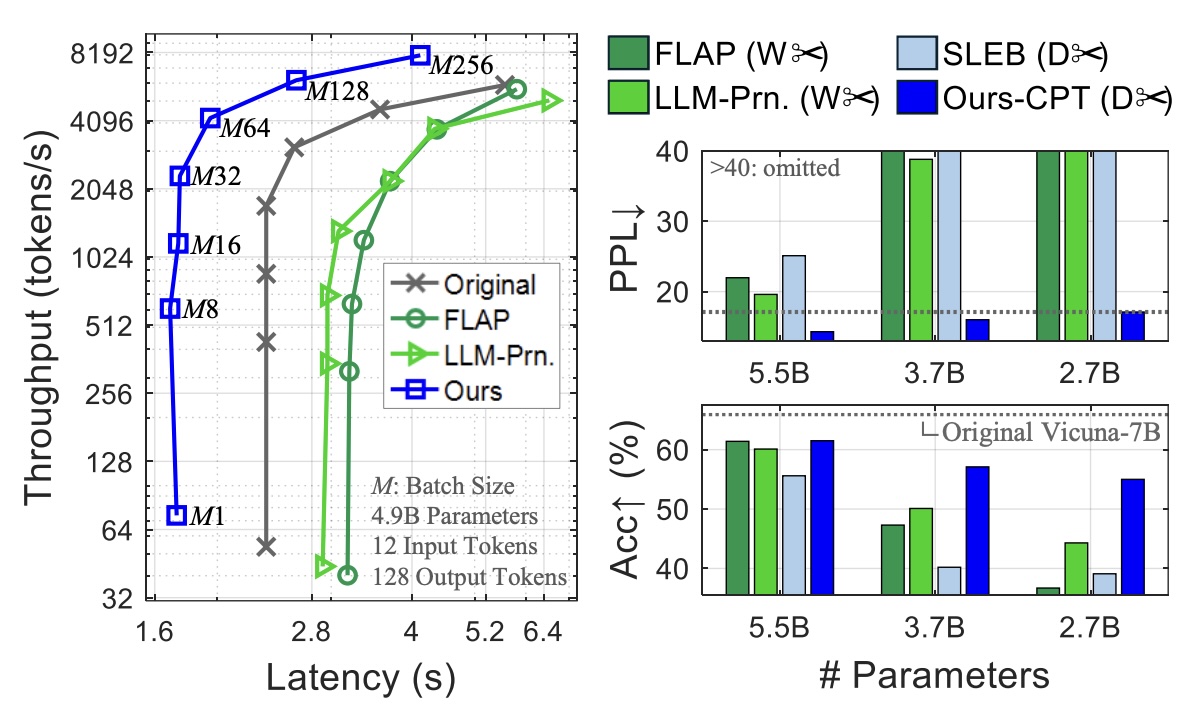
Presents a straightforward depth pruning strategy for LLMs that removes entire transformer layers, yielding smaller models with minimal performance loss.

Unifies pruning, quantization, and knowledge distillation into a single framework to compress talking-face generation models for real-time inference.
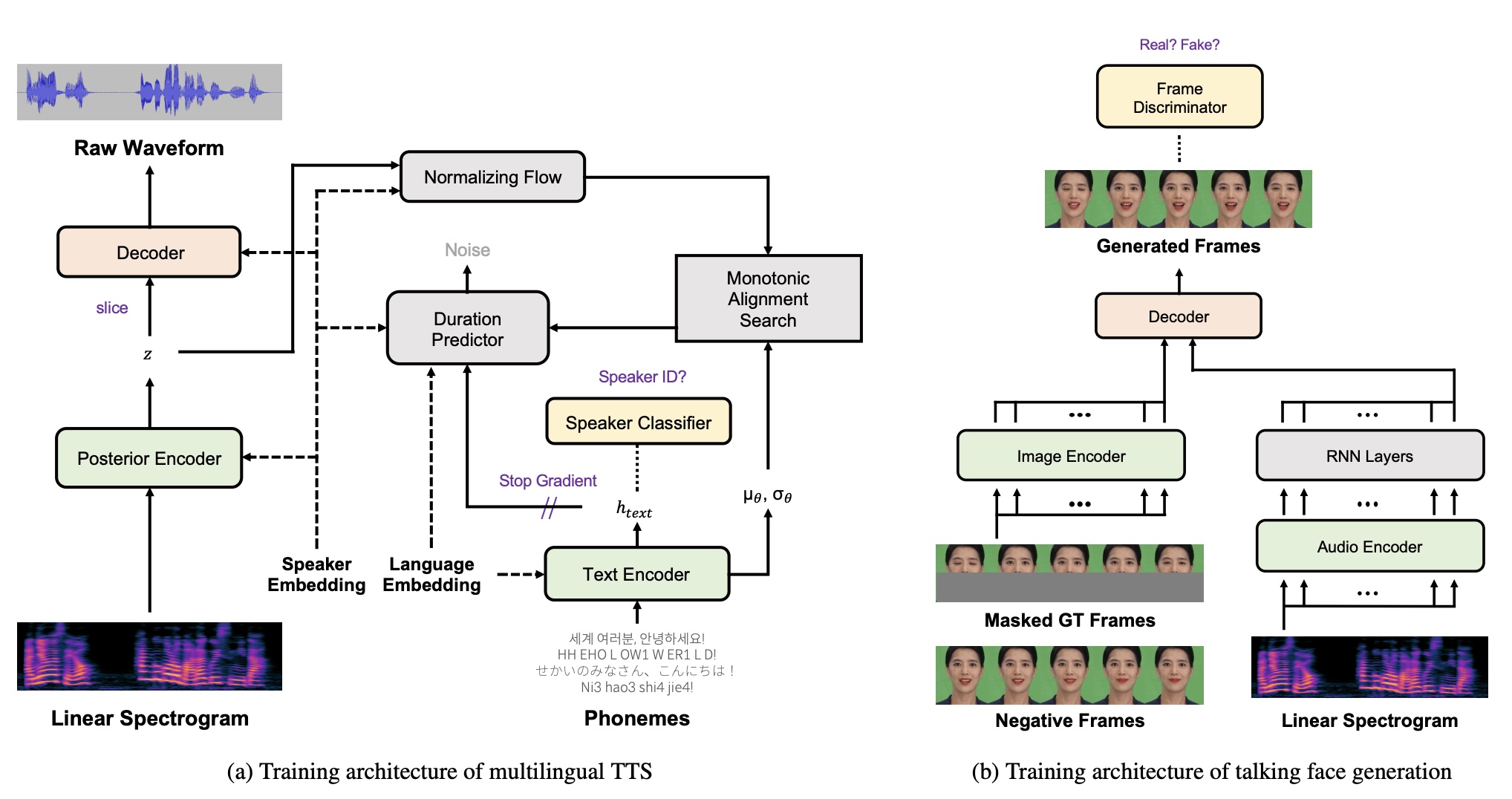
Combines multilingual text-to-speech with lip-synced face generation, enabling talking-face videos in multiple languages from a single text input.
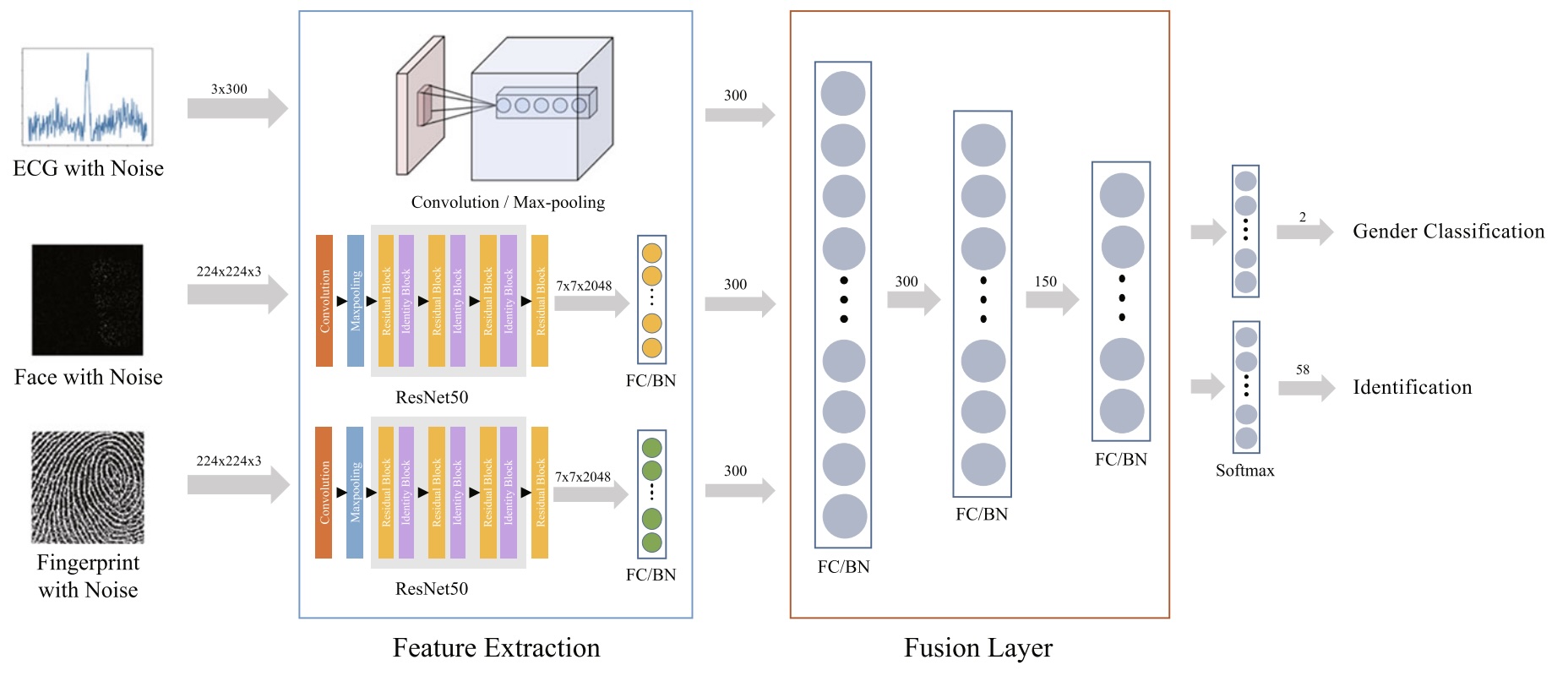
Proposes a deep learning model that fuses multiple biometric signals for robust user identification, outperforming single-modality baselines.